实验3-Hudi实行欧盟GDPR删除
GDPR 删除
实验目录:
GDPR已使删除成为每个人数据管理工具箱中的必备工具。通过允许用户指定不同的记录有效载荷实现,Apache Hudi支持对存储在Hudi数据集中的数据执行两种类型的删除。
-
Soft Deletes : 使用软删除时,用户希望保留键,但仅使所有其他字段的值都为空。通过确保适当的字段在数据集架构中可以为空,并在将这些字段设置为null之后简单地向上更新数据集,即可轻松实现这一点。
-
Hard Deletes : 硬删除是一种更强形式,他从数据集中物理删除数据记录的任何痕迹。
现在让我们对数据集执行一些删除操作。
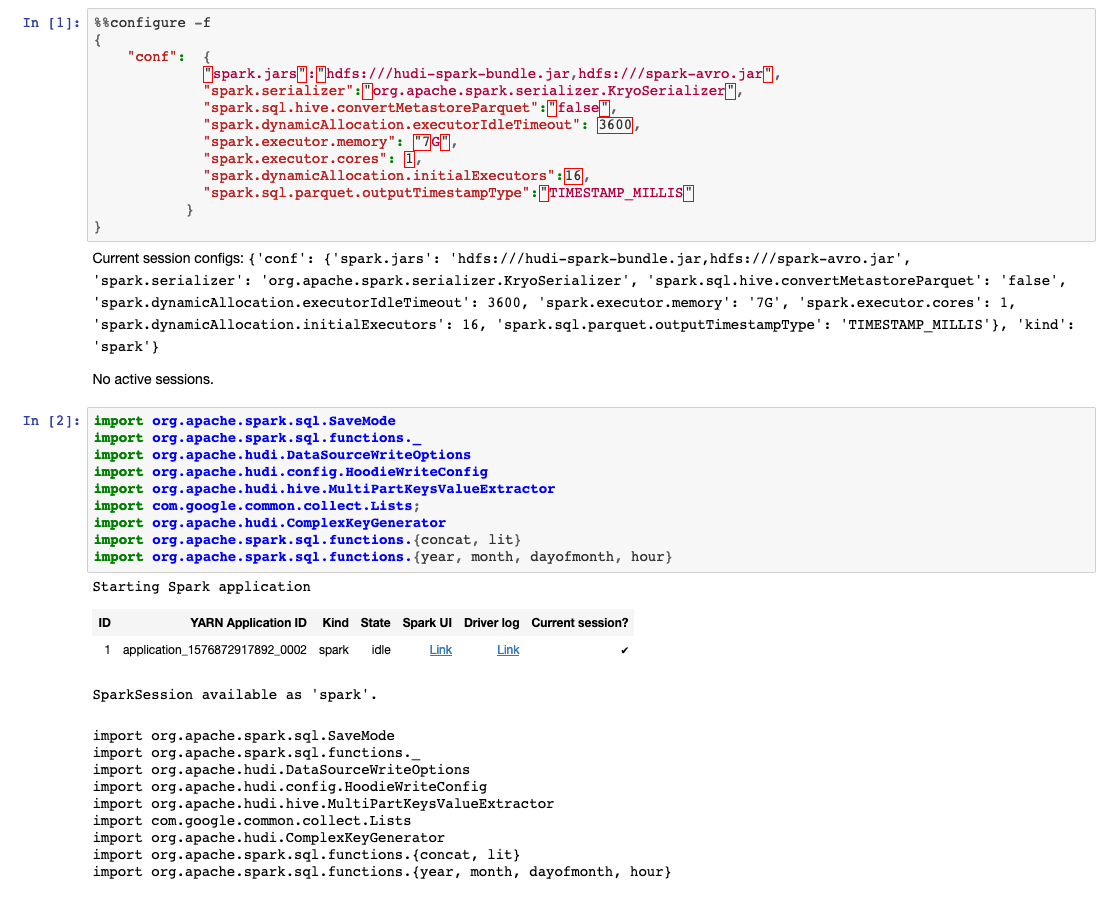
%%configure -f
{
"conf": {
"spark.jars":"hdfs:///hudi-spark-bundle.jar,hdfs:///spark-avro.jar",
"spark.serializer":"org.apache.spark.serializer.KryoSerializer",
"spark.sql.hive.convertMetastoreParquet":"false",
"spark.dynamicAllocation.executorIdleTimeout": 3600,
"spark.executor.memory": "7G",
"spark.executor.cores": 1,
"spark.dynamicAllocation.initialExecutors":16,
"spark.sql.parquet.outputTimestampType":"TIMESTAMP_MILLIS"
}
}
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.functions._
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieWriteConfig
import org.apache.hudi.hive.MultiPartKeysValueExtractor
import com.google.common.collect.Lists;
import org.apache.hudi.ComplexKeyGenerator
import org.apache.spark.sql.functions.{concat, lit}
import org.apache.spark.sql.functions.{year, month, dayofmonth, hour}
Soft_Deletes
让我们选择一些记录来测试软删除功能:
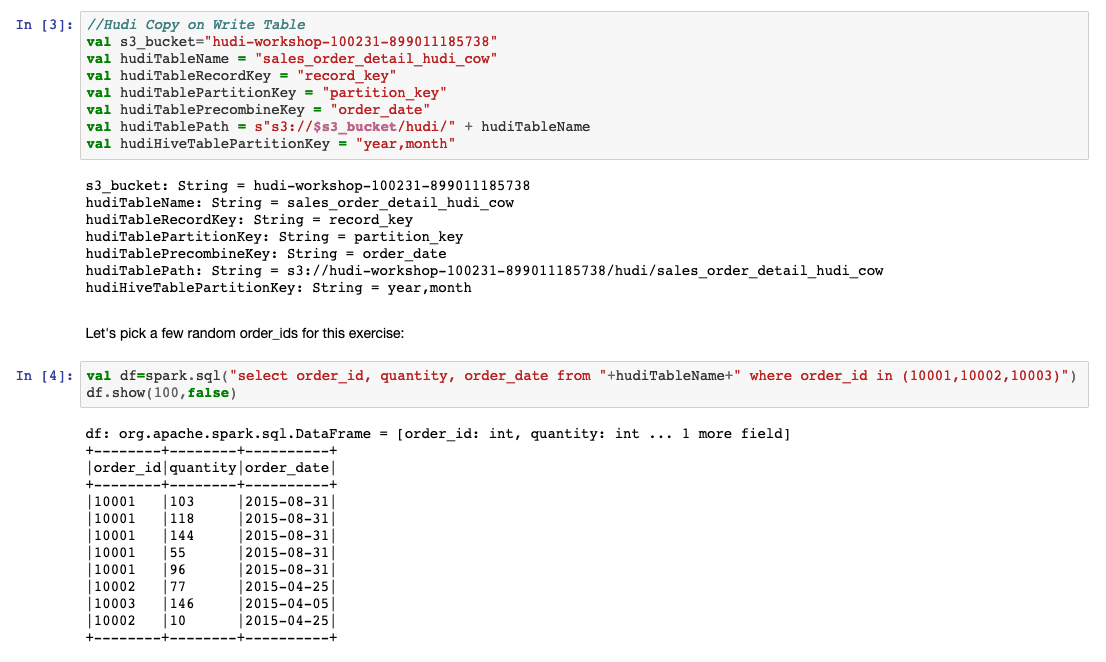
//Hudi Copy on Write Table
val s3_bucket="###s3_bucket###"
val hudiTableName = "sales_order_detail_hudi_cow"
val hudiTableRecordKey = "record_key"
val hudiTablePartitionKey = "partition_key"
val hudiTablePrecombineKey = "order_date"
val hudiTablePath = s"s3://$s3_bucket/hudi/" + hudiTableName
val hudiHiveTablePartitionKey = "year,month"
让我们为该练习选择一些随机的order_id:
val df=spark.sql("select order_id, quantity, order_date from "+hudiTableName+" where order_id in (10001,10002,10003)")
df.show(100,false)
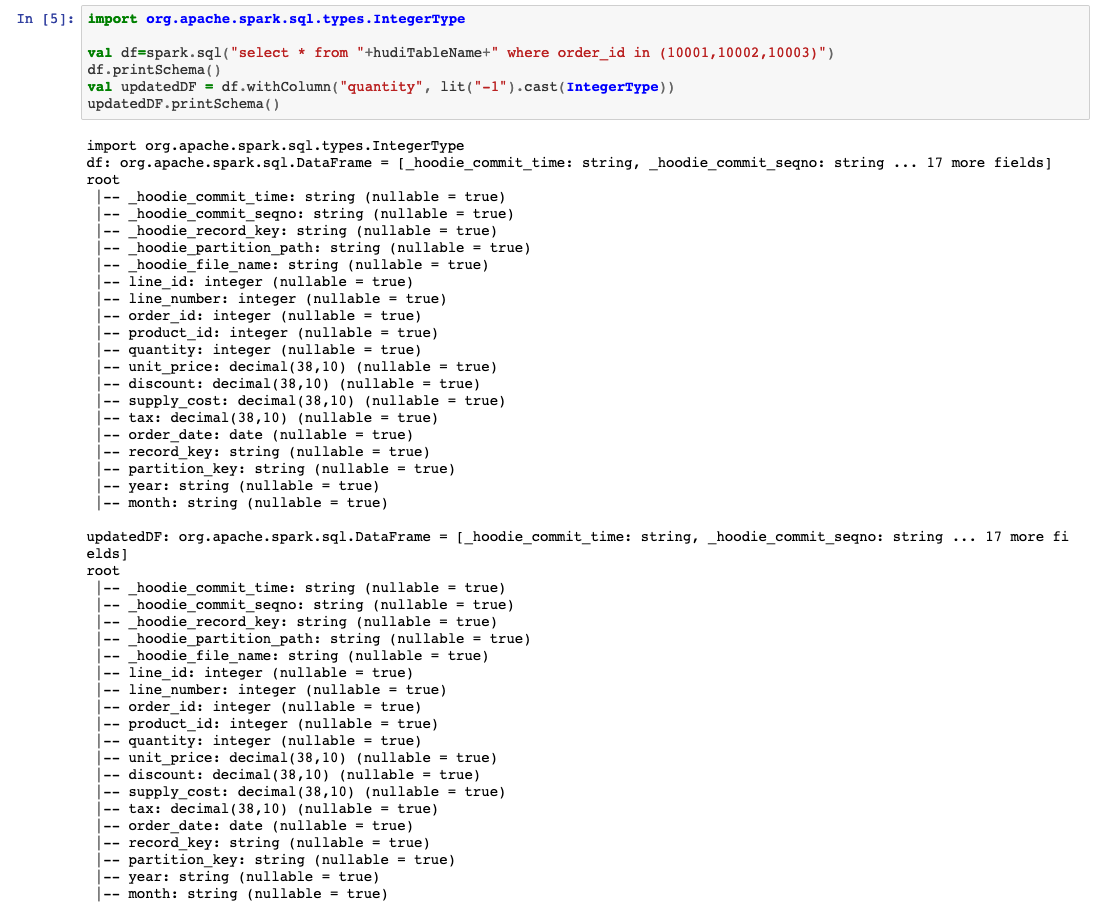
import org.apache.spark.sql.types.IntegerType
val df=spark.sql("select * from "+hudiTableName+" where order_id in (10001,10002,10003)")
df.printSchema()
val updatedDF = df.withColumn("quantity", lit("-1").cast(IntegerType))
updatedDF.printSchema()
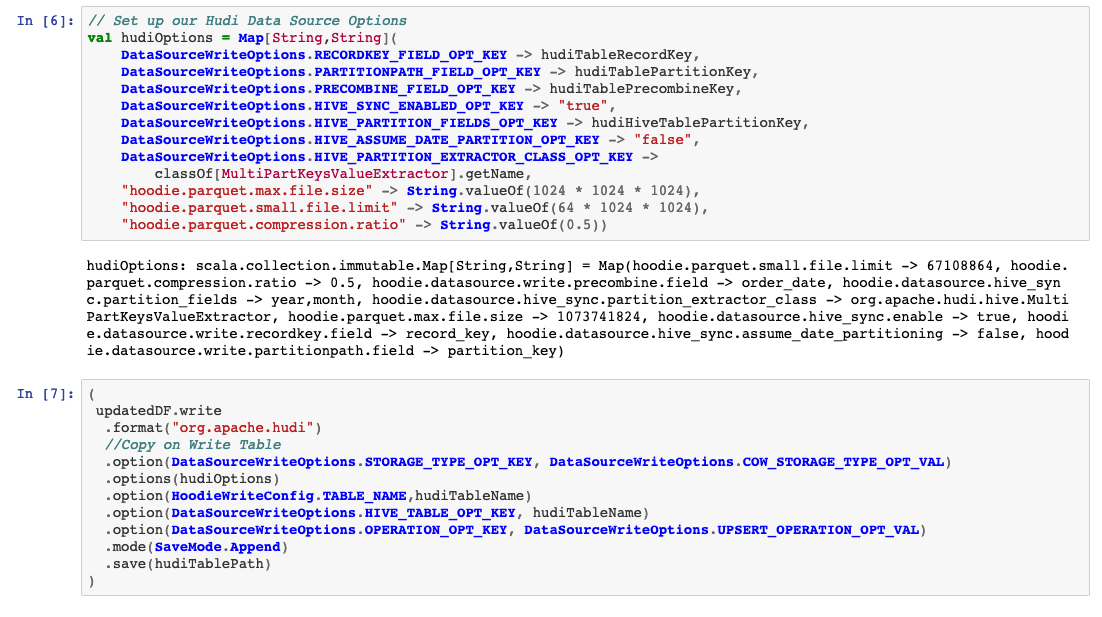
设置我们的Hudi数据源选项
val hudiOptions = Map[String,String](
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> hudiTableRecordKey,
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> hudiTablePartitionKey,
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> hudiTablePrecombineKey,
DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true",
DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> hudiHiveTablePartitionKey,
DataSourceWriteOptions.HIVE_ASSUME_DATE_PARTITION_OPT_KEY -> "false",
DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY ->
classOf[MultiPartKeysValueExtractor].getName,
"hoodie.parquet.max.file.size" -> String.valueOf(128 * 1024 * 1024),
"hoodie.parquet.small.file.limit" -> String.valueOf(64 * 1024 * 1024),
"hoodie.parquet.compression.ratio" -> String.valueOf(0.5))
(
updatedDF.write
.format("org.apache.hudi")
//Copy on Write Table
.option(DataSourceWriteOptions.STORAGE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_STORAGE_TYPE_OPT_VAL)
.options(hudiOptions)
.option(HoodieWriteConfig.TABLE_NAME,hudiTableName)
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, hudiTableName)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
.mode(SaveMode.Append)
.save(hudiTablePath)
)
现在让我们查看表中更改的数据:
val df=spark.sql("select order_id, quantity, order_date from "+hudiTableName+" where order_id in (10001,10002,10003)")
df.show(100,false)
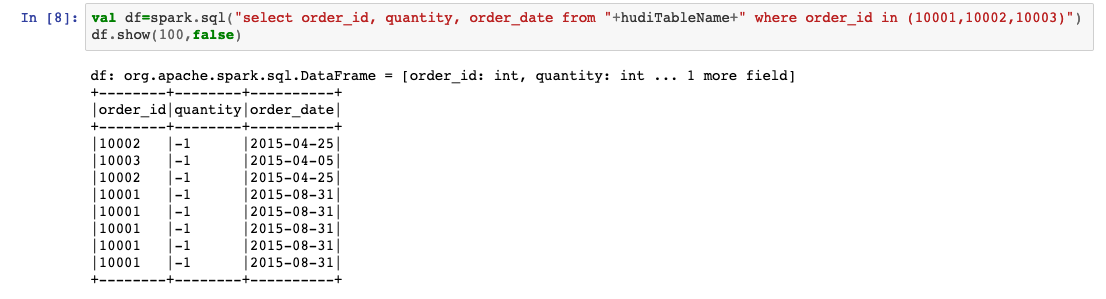
我们可以看到数量字段已更新。因此,从本质上讲,软删除是一种清除某些字段的更新。您通常会对PII或PHI列执行此操作以使记录匿名。
Hard_Deletes
让我们测试硬删除功能:
val deleteDF=spark.sql("select * from "+hudiTableName+" where order_id in (10001,10002,10003)")
deleteDF.count()
(
deleteDF.write
.format("org.apache.hudi")
.option(DataSourceWriteOptions.STORAGE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_STORAGE_TYPE_OPT_VAL)
.options(hudiOptions)
.option(HoodieWriteConfig.TABLE_NAME,hudiTableName)
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, hudiTableName)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
// Empty out the row with the EmptyHoodieRecordPayload
.option(DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY, "org.apache.hudi.EmptyHoodieRecordPayload")
.mode(SaveMode.Append)
.save(hudiTablePath)
)
val df=spark.sql("select * from "+hudiTableName+" where order_id in (10001,10002,10003)")
df.count()
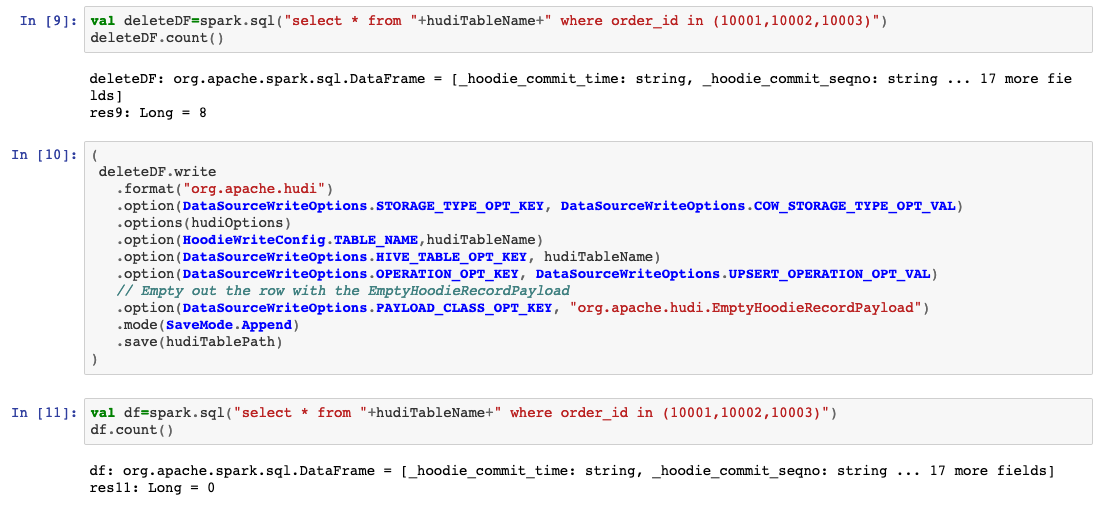 我们可以看到记录已从我们的数据湖中删除。
我们可以看到记录已从我们的数据湖中删除。