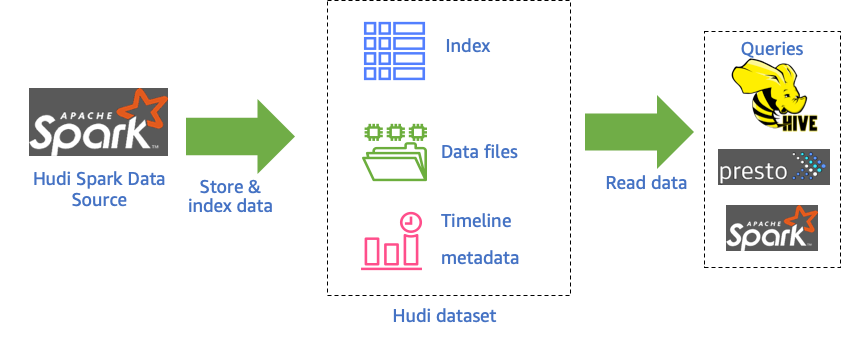
Hudi如何工作
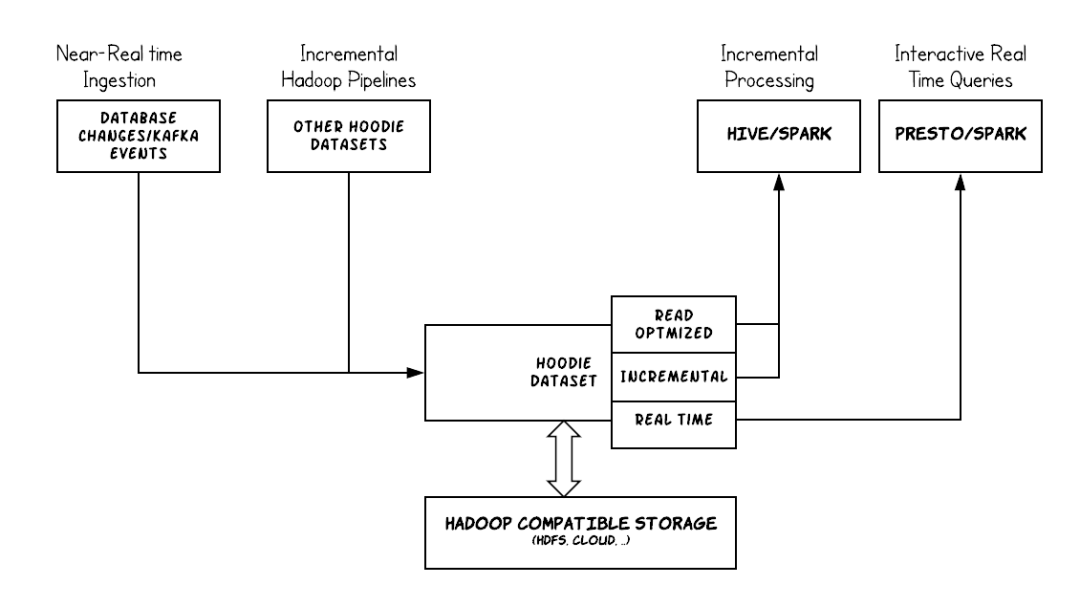
将Hudi与Amazon EMR结合使用时,可以使用Spark Data Source API或Hudi DeltaStreamer程序将数据写入数据集中。 Hudi将数据集调度存放到类似于传统Hive表的基本路径下的分区目录结构中。在这些目录中的文件中,数据的布局方式具体取决于您选择的数据集类型。您可以选择写入时复制(CoW)或读取时合并(MoR)。
无论数据集的类型是哪种,数据集中的每个分区均由其基本路径的partitionpath作为唯一标识。在每个分区内,记录被分布到多个数据文件中。 Hudi中的每个动作都有一个相应的提交,该提交由提交时瞬间的时间戳以递增的形式进行标识。 Hudi会将一系列在数据集上执行的所有动作作为时间轴保留。 Hudi依靠时间轴在读取器和写入器之间提供快照隔离,并能够回滚到上一个时间点。有关Hudi记录的操作以及操作状态的更多信息,请参阅Apache Hudi文档中的时间轴。
下图是hudi的定义概览,涉及存储类型,视图两个主要概念