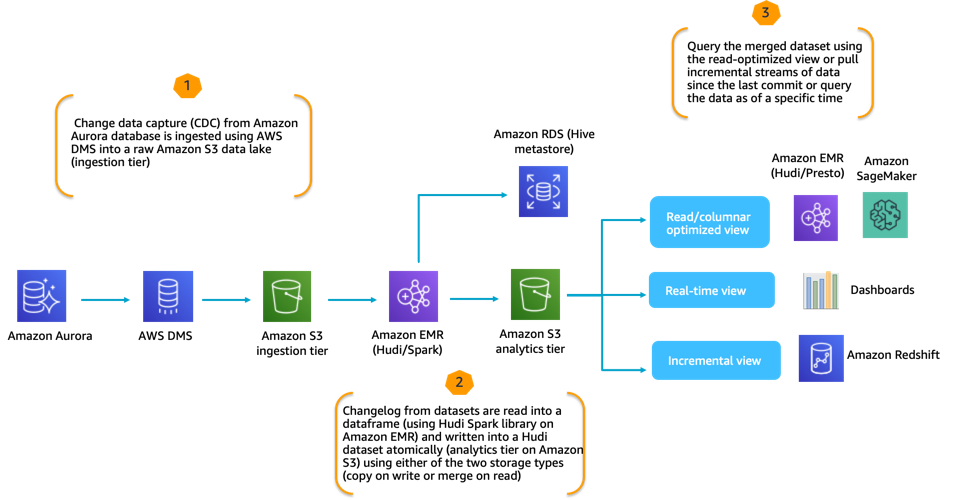
实验系统架构
以下是您将使用的数据管道的体系结构流程。它首先使用Amazon Data Migration Service(DMS)从OLTP数据库(例如Amazon Aurora)中提取数据。 DMS以Parquet格式将数据文件存储到S3数据湖原始层的存储桶中。 DMS任务的配置方式是将全量加载以及更改数据捕获都拉到原始S3存储桶。然后,运行Amazon EMR集群的Spark会读取数据,并将其作为Apache Hudi数据集写入数据湖分析层中的S3存储桶。 Hudi可以在两种不同的存储类型中写入数据,并在三种不同的视图中公开所写入的数据:
a.)读取的优化视图,可以使用在Amazon EMR上运行的Presto或用于机器学习需要的工具查询
b.)可以支持近实时报表仪表板的视图
c.)可用于填充数据仓库(例如Redshift)的增量视图