实验2-Hudi+S3+EMR增量数仓
使用Apache Hudi支撑对S3数据湖流式更新的查询
实验目录:
概览
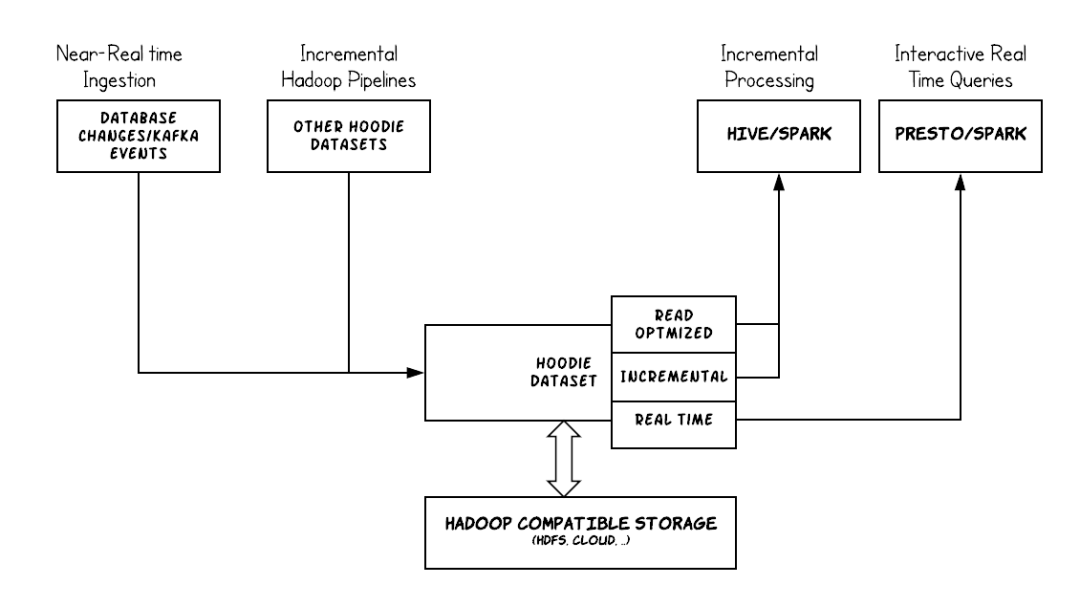
该笔记本演示使用 Apache Hudi 在Amazon EMR上的使用,以支撑对S3数据湖的流更新。
这里有一些很好的参考链接,供以后阅读:
查询原始数据
让我们首先初始化Spark会话,以将此笔记本连接到我们的Spark EMR集群:
%%configure -f
{
"conf": {
"spark.jars":"hdfs:///hudi-spark-bundle.jar,hdfs:///spark-avro.jar",
"spark.serializer":"org.apache.spark.serializer.KryoSerializer",
"spark.sql.hive.convertMetastoreParquet":"false",
"spark.dynamicAllocation.executorIdleTimeout": 3600,
"spark.executor.memory": "7G",
"spark.executor.cores": 1,
"spark.dynamicAllocation.initialExecutors":16,
"spark.sql.parquet.outputTimestampType":"TIMESTAMP_MILLIS"
}
}
def execute_sql(sql):
conn.query(sql)
result = conn.store_result()
for i in range(result.num_rows()):
print(result.fetch_row())
val s3_bucket="###s3_bucket###"
val dataPath=s"s3://$s3_bucket/dms-full-load-path/salesdb/SALES_ORDER_DETAIL/LOAD*"
以上代码的运行您将获得如下的返回
现在让我们从DataLake的原始数据层的SALES_ORDER_DETAIL表中读取数据:
var df=spark.read.parquet(dataPath)
df=df.toDF(df.columns map(_.toLowerCase): _*)
df.printSchema()
df.count()
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.functions._
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieWriteConfig
import org.apache.hudi.hive.MultiPartKeysValueExtractor
import com.google.common.collect.Lists;
import org.apache.hudi.ComplexKeyGenerator
import org.apache.spark.sql.functions.{concat, lit}
import org.apache.spark.sql.functions.{year, month, dayofmonth, hour}
创建写时复制表
Copy on Write Tables 存储类型仅使用列文件格式(例如 parquet)存储数据。通过在写入过程中执行同步合并,仅更新版本并重写文件。
//Hudi Copy on Write Table
val hudiTableName = "sales_order_detail_hudi_cow"
val hudiTableRecordKey = "record_key"
val hudiTablePartitionKey = "partition_key"
val hudiTablePrecombineKey = "order_date"
val hudiTablePath = s"s3://$s3_bucket/hudi/" + hudiTableName
val hudiHiveTablePartitionKey = "year,month"
// Add Primary Key - RECORD_KEY
var inputDF = df.withColumn(hudiTableRecordKey, concat(col("order_id"), lit("#"), col("line_id")))
inputDF=inputDF.select(inputDF.columns.map(x => col(x).as(x.toLowerCase)): _*)
我们将执行一些转换,以确保分区列YEAR和MONTH为字符串类型。
{
import org.apache.spark.sql.types.DateType
import org.apache.spark.sql.types.StringType
inputDF = inputDF.withColumn("order_date", inputDF("order_date").cast(DateType))
inputDF = inputDF.withColumn("year",year($"order_date").cast(StringType))
.withColumn("month",month($"order_date").cast(StringType))
inputDF = inputDF.withColumn(hudiTablePartitionKey,concat(lit("year="),$"year",lit("/month="),$"month"))
inputDF.first()
}
inputDF.printSchema()
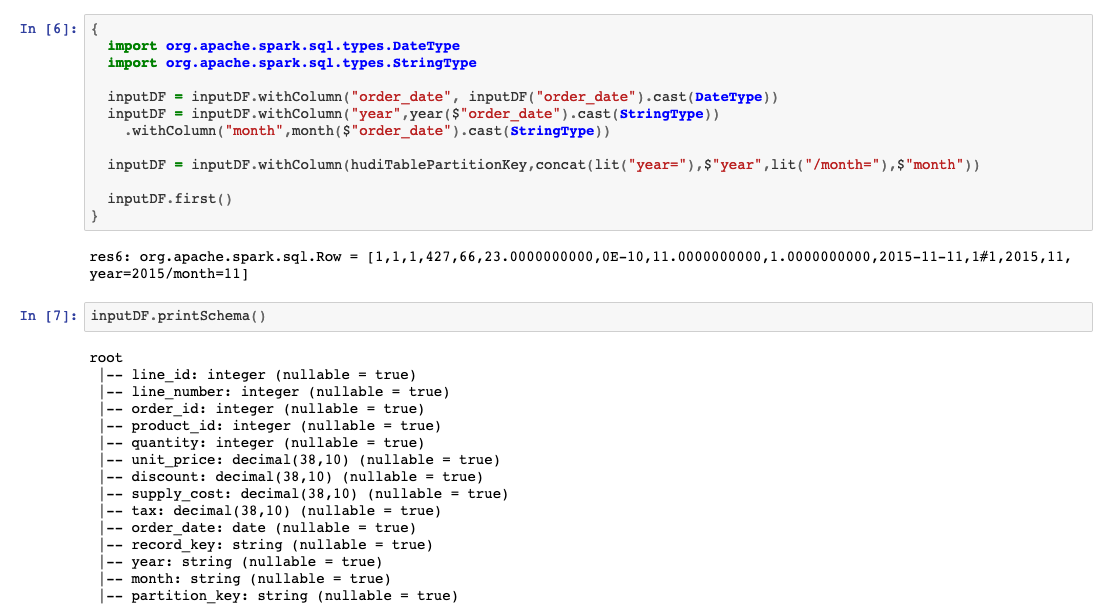
现在已经准备好输入数据,让我们在DaraLake的Analytics(分析)层中编写数据以创建Hudi COW表:
// Set up our Hudi Data Source Options
val hudiOptions = Map[String,String](
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> hudiTableRecordKey,
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> hudiTablePartitionKey,
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> hudiTablePrecombineKey,
DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true",
DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> hudiHiveTablePartitionKey,
DataSourceWriteOptions.HIVE_ASSUME_DATE_PARTITION_OPT_KEY -> "false",
DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY ->
classOf[MultiPartKeysValueExtractor].getName,
"hoodie.parquet.max.file.size" -> String.valueOf(1024 * 1024 * 1024),
"hoodie.parquet.small.file.limit" -> String.valueOf(64 * 1024 * 1024),
"hoodie.parquet.compression.ratio" -> String.valueOf(0.5),
"hoodie.insert.shuffle.parallelism" -> String.valueOf(2))
(
inputDF.write
.format("org.apache.hudi")
//Copy on Write Table
.option(DataSourceWriteOptions.STORAGE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_STORAGE_TYPE_OPT_VAL)
.options(hudiOptions)
.option(HoodieWriteConfig.TABLE_NAME,hudiTableName)
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, hudiTableName)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL)
.mode(SaveMode.Overwrite)
.save(hudiTablePath)
)

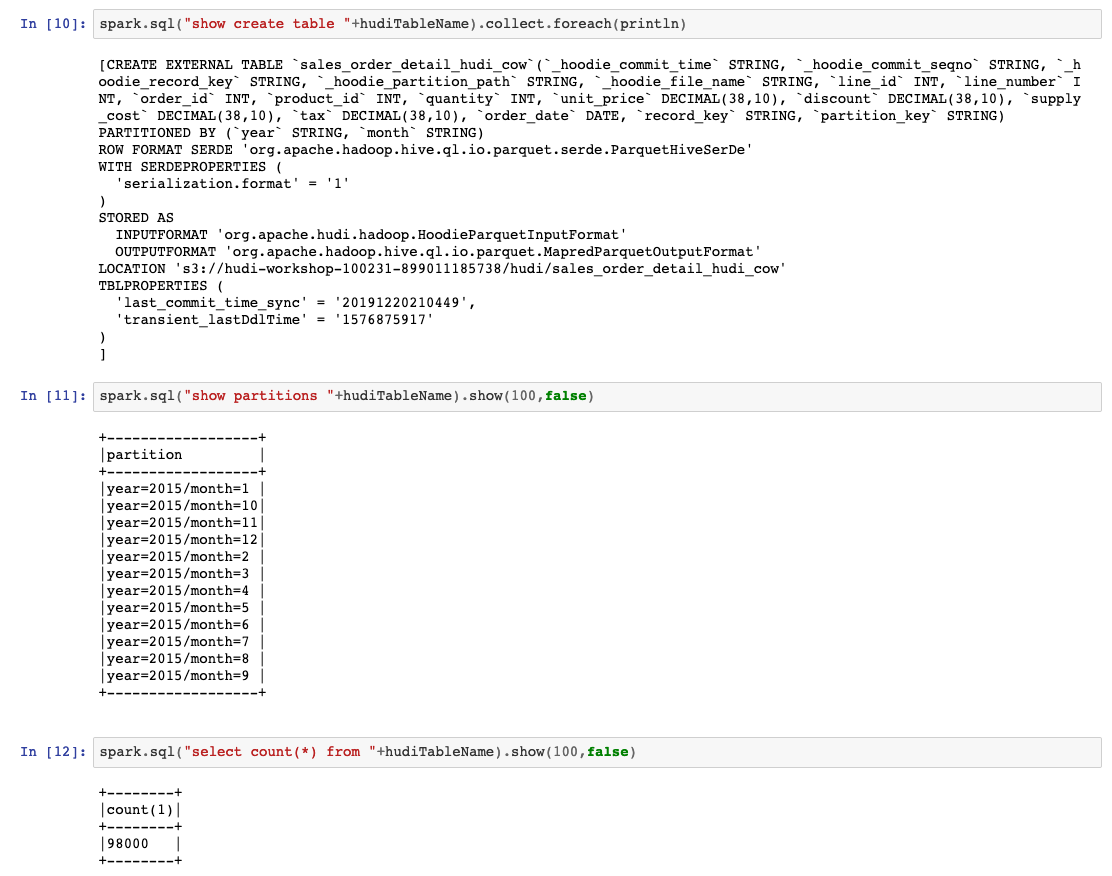
现在,我们可以查看和查询在Spark-SQL中创建的表:
spark.sql("show create table "+hudiTableName).collect.foreach(println)
spark.sql("show partitions "+hudiTableName).show(100,false)
spark.sql("select count(*) from "+hudiTableName).show(100,false)
创建读时合并表
Merge on Read 存储类型使客户端可以将数据快速提取为基于行的数据格式,例如Avro。使用MOR表类型写入Hudi数据集的任何新数据,都将写入新的日志/增量文件,这些文件在内部将数据存储为Avro编码的字节。
压缩过程(配置为内联或异步)会将日志文件格式转换为列式基本文件格式(parquet)。两种不同的InputFormats体现了此数据的2种不同视图:
- 读优化视图将展现出parquet格式列存储的读取性能
- 实时视图将展现出列式存储的 与 行式日志形式的 不同的性能.
在Merge on Read存储模式下,更新现有的一组行将导致以下两种情况:
-
a)从以前的压缩生成的现有基础 parquet 文件伴随log/delta文件
-
b) 写入的更新一个 log/delta file in case no compaction ever happened for it. 因此,对此类数据集的所有写入均受avro/log文件写入性能的限制, 比parquet快得多. 然而, 读取log/delta 文件 比读取列格式的 (parquet) 文件要求更高的读取成本.
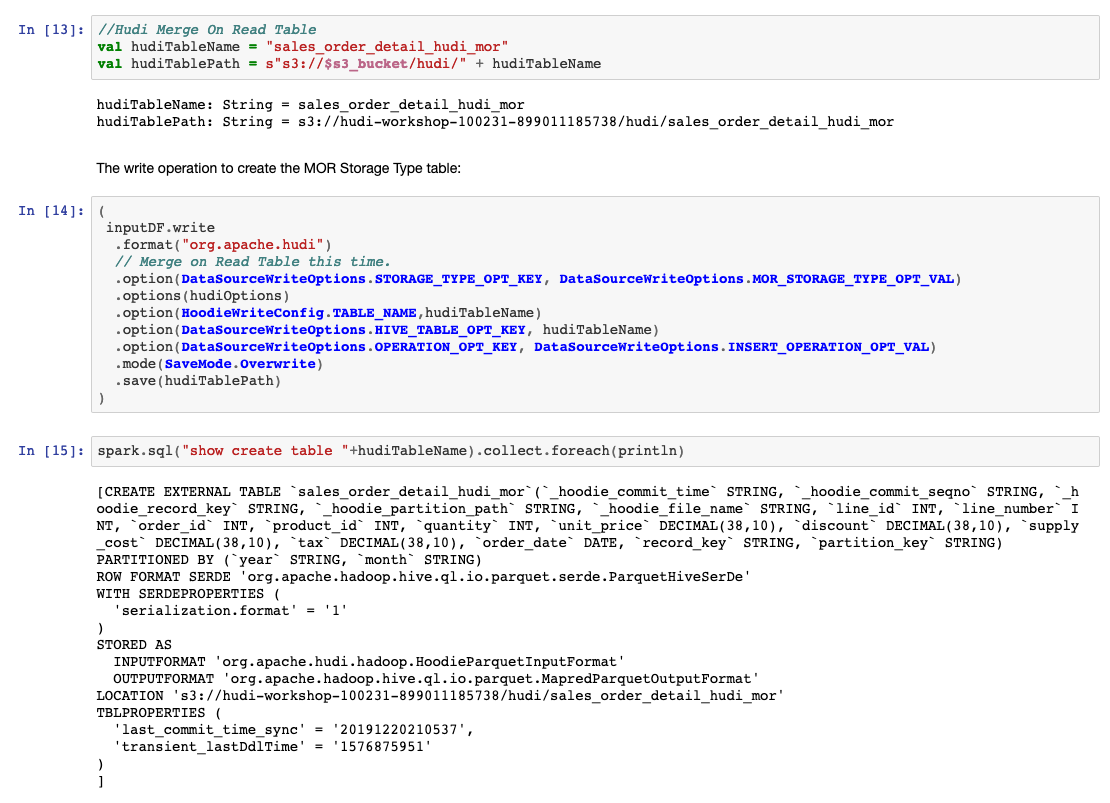
//Hudi Merge On Read Table
val hudiTableName = "sales_order_detail_hudi_mor"
val hudiTablePath = s"s3://$s3_bucket/hudi/" + hudiTableName
创建MOR存储类型表的写操作:
(
inputDF.write
.format("org.apache.hudi")
// Merge on Read Table this time.
.option(DataSourceWriteOptions.STORAGE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_STORAGE_TYPE_OPT_VAL)
.options(hudiOptions)
.option(HoodieWriteConfig.TABLE_NAME,hudiTableName)
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, hudiTableName)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL)
.mode(SaveMode.Overwrite)
.save(hudiTablePath)
)
spark.sql("show create table "+hudiTableName).collect.foreach(println)
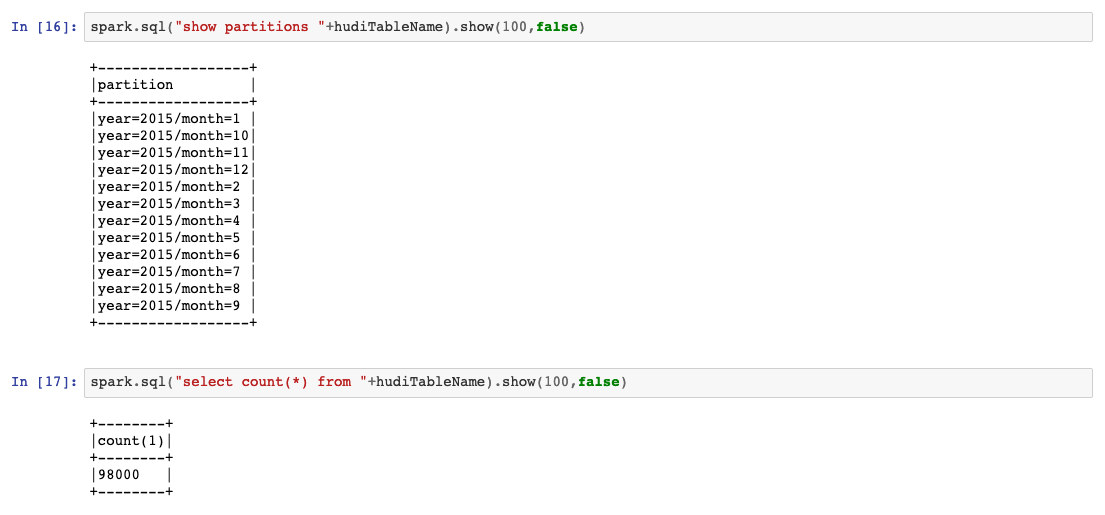
spark.sql("show partitions "+hudiTableName).show(100,false)
spark.sql("select count(*) from "+hudiTableName).show(100,false)
从Presto和Hive查询表
您可以从Jupyter终端SSH或者您的本地连接到Spark Presto集群,请将key替换为您自己的key:
$> cd SageMaker
$> chmod 400 ee-default-keypair.pem
$> ssh -i ee-default-keypair.pem hadoop@###emr_presto_cluster_master###
$> presto-cli
查询数据:
presto> use hive.default;
presto> show tables;
presto> select count(*) from sales_order_detail_hudi_cow;
presto> select count(*) from sales_order_detail_hudi_mor;
请使用 Ctrl+D to 退出 Presto-cli, 并运行以下命令运行hive
$> hive
# 查看表格
hive> show tables;
Note: 在执行下一步之前,请确保在此笔记本上运行内核->关闭。这将释放Spark EMR群集上的资源以用于下一步。
流式数据更新到写时复制表
Note: 需要从Jupyter中可用的终端执行以下步骤。请在第一个笔记本中启动“模拟随机更新”步骤
从Jupyter终端SSH到Spark EMR集群:
$> cd SageMaker
$> chmod 400 ee-default-keypair.pem
$> ssh -i ee-default-keypair.pem hadoop@###emr_spark_cluster_master###
一旦进入EMR集群,请在终端中运行以下命令:
EMR $> spark-submit --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" --conf "spark.sql.hive.convertMetastoreParquet=false" --conf "spark.dynamicAllocation.maxExecutors=10" --jars hdfs:///hudi-spark-bundle.jar --jars hdfs:///spark-avro.jar --packages org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.2 --class com.hudiConsumer.SparkKafkaConsumerHudiProcessor_COW SparkKafkaConsumerHudiProcessor-assembly-1.0.jar ###s3_bucket### ###kafka_brokers###
该命令启动一个Spark Streaming作业,该作业连续监视Kafka主题“ s3_event_streams”,以将更新消耗到S3中的Hudi表“ sales_order_detail_hudi_cow”中
查询变更的数据
您可以从Jupyter终端SSH到Spark Presto集群:
$> cd SageMaker
$> ssh -i ee-default-keypair.pem hadoop@###emr_presto_cluster_master###
$> presto-cli
查询数据:
presto> use hive.default;
presto> show tables;
# 在这里选择一个记录键
presto> select record_key,quantity,month from sales_order_detail_hudi_cow where record_key = '<record_key>';
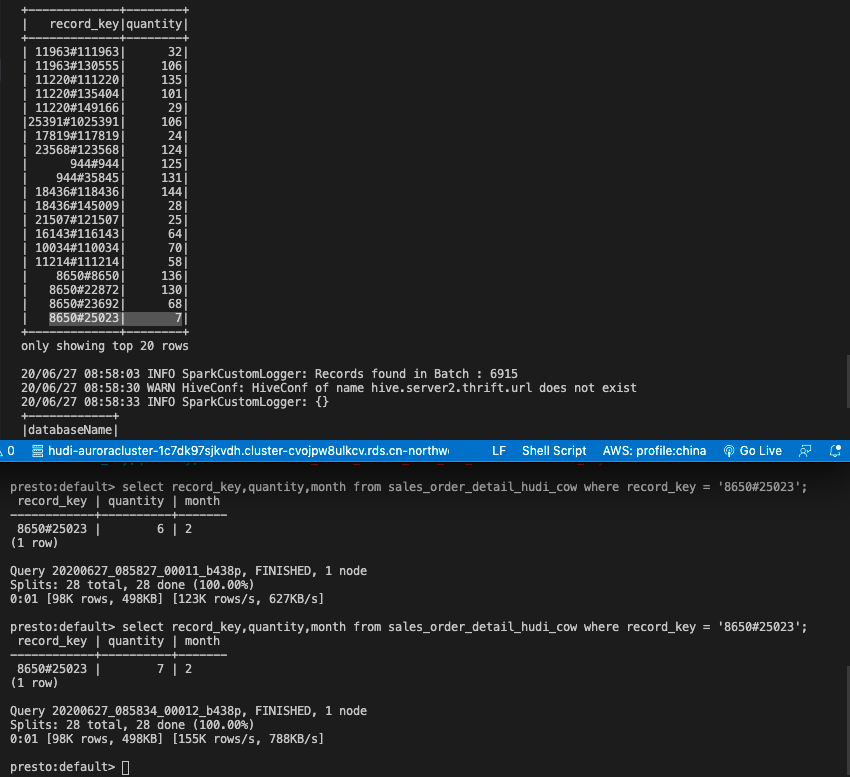
Note: 请在连接到EMR Spark Cluster的终端中按Ctrl + C,以停止Spark Streaming作业
流式数据更新到读时合并表
从Jupyter终端SSH到Spark EMR集群:
ssh -i ee-default-keypair.pem hadoop@###emr_spark_cluster_master###
当你进入EMR集群,请在终端中运行以下命令:
spark-submit --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" --conf "spark.sql.hive.convertMetastoreParquet=false" --conf "spark.dynamicAllocation.maxExecutors=10" --jars hdfs:///hudi-spark-bundle.jar --jars hdfs:///spark-avro.jar --packages org.apache.spark:spark-streaming-kafka-0-10_2.11:2.4.2 --class com.hudiConsumer.SparkKafkaConsumerHudiProcessor_MOR SparkKafkaConsumerHudiProcessor-assembly-1.0.jar ###s3_bucket### ###kafka_brokers###
该命令启动一个Spark Streaming作业,该作业连续监视Kafka主题“ s3_event_streams”,以将更新消耗到S3中的Hudi表“ sales_order_detail_hudi_mor”中
查询变化的数据
您可以从Jupyter终端SSH到Spark Presto集群:
ssh -i ee-default-keypair.pem hadoop@###emr_presto_cluster_master###
并查询数据,但是这次我们将使用Hive来运行查询:
$> hive
# view the tables
hive> show tables;
# 在这里选择一个记录键
hive> select record_key,quantity,month from sales_order_detail_hudi_mor where record_key = '<record_key>';
# 让我们查询实时表中的相同记录
hive> select record_key,quantity,month from sales_order_detail_hudi_mor_rt where record_key = '<record_key>';
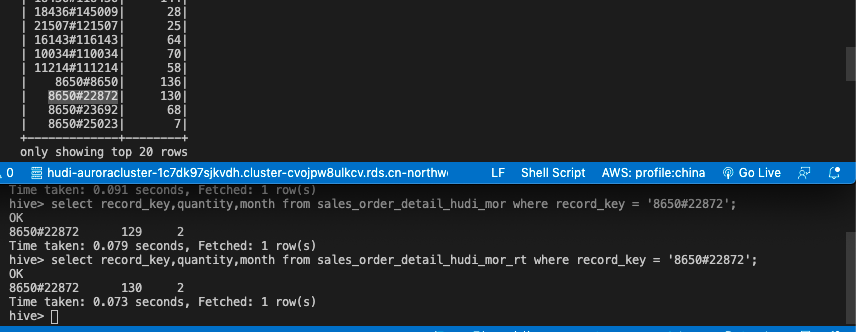 我们可以看到,实时表具有最新的变更视图,但尚未压缩到我们的主MOR基础表中。
我们可以看到,实时表具有最新的变更视图,但尚未压缩到我们的主MOR基础表中。
运行Hudi读写数据的处理过程
Let’s now run the Apache Hudi Compaction process manually so that we understand the behavior. These steps will typically be automated in a production environment.
## 在终端上,让我们连接到Spark EMR集群并启动hudi cli
$> /usr/lib/hudi/cli/bin/hudi-cli.sh
## 在hudi cli,我们连接到MOR表的数据路径
hudi-> connect --path s3://###s3_bucket###/hudi/sales_order_detail_hudi_mor
## 在此表上运行查看描述
hudi:sales_order_detail_hudi_mor-> desc
## 查看待处理的提交
hudi:sales_order_detail_hudi_mor-> commits show
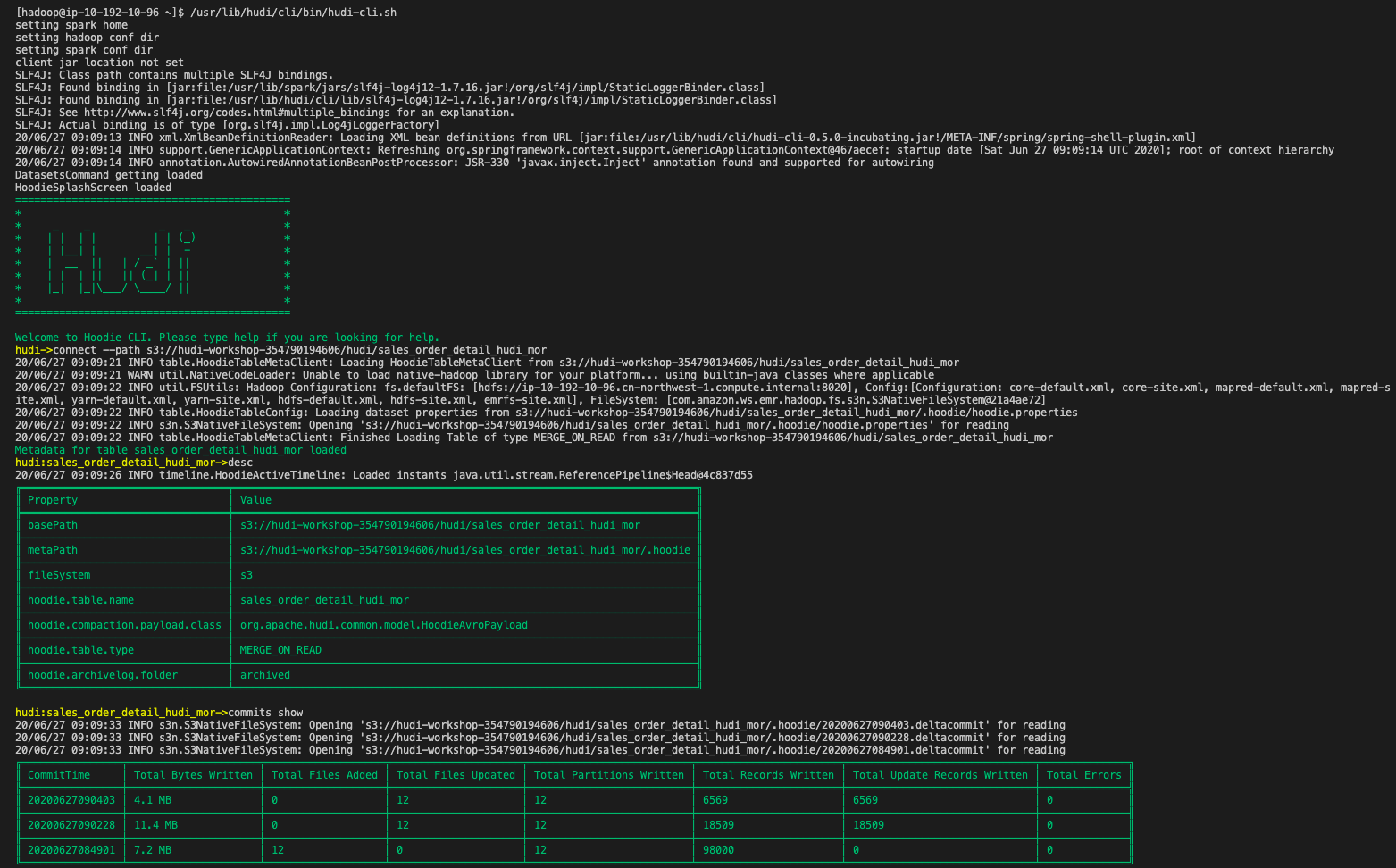
## 在表示上执行压缩
hudi:sales_order_detail_hudi_mor-> `compaction schedule`
## 压缩计划成功后刷新hudi元数据
hudi-> connect --path s3://###s3_bucket###/hudi/sales_order_detail_hudi_mor
## 查看待处理的压缩
hudi:sales_order_detail_hudi_mor->` compactions show all`
## 在表示上执行压缩
hudi:sales_order_detail_hudi_mor-> compaction run --parallelism 12 --sparkMemory 100GB --retry 1 --compactionInstant <compactionInstant> --schemaFilePath s3://###s3_bucket###/config/sales_order_detail.schema
## refresh hudi metadata after compactions run is successful
hudi-> connect --path s3://###s3_bucket###/hudi/sales_order_detail_hudi_mor
## 查看完成的压缩
hudi:sales_order_detail_hudi_mor-> `compactions show all`
## 压缩应显示“立即完成”。让我们查看提交并查询Hive中的更改:
hudi:sales_order_detail_hudi_mor-> `commits show`
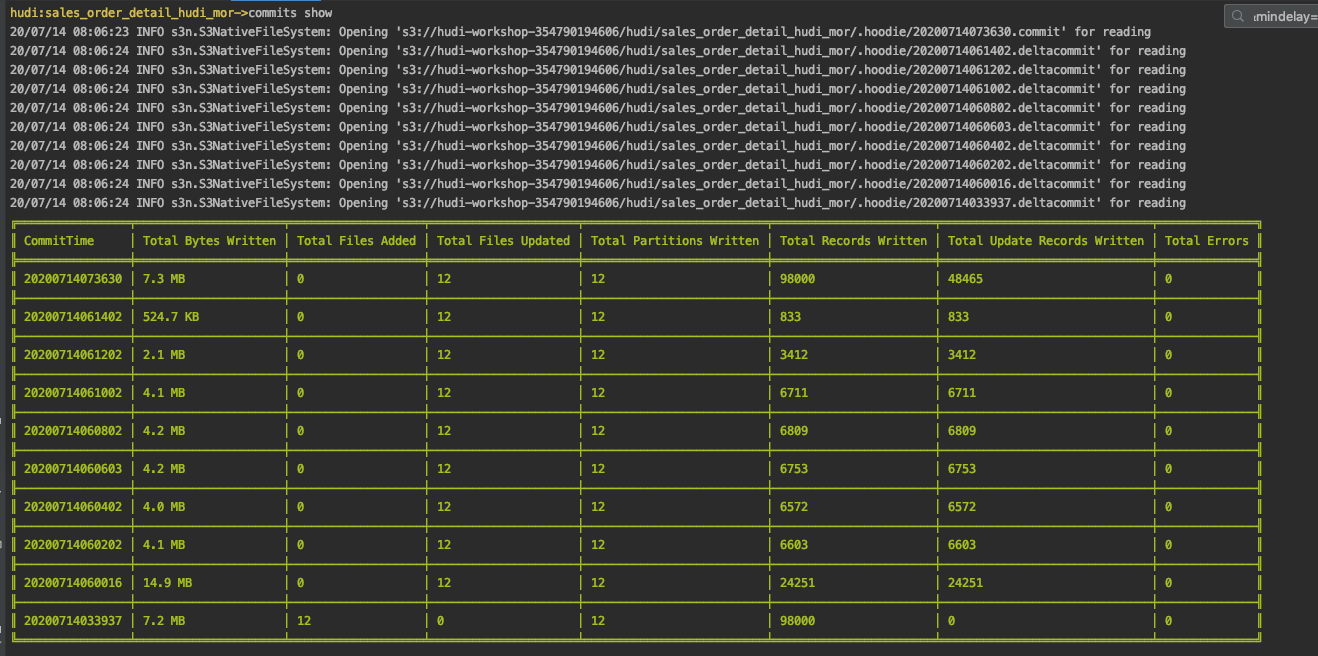
## 现在让我们回滚最新的提交。
hudi:sales_order_detail_hudi_mor-> `commit rollback --commit <latest commit id>`
## 步骤完成后,让我们再次查看提交并在Hive中查询更改:
hudi:sales_order_detail_hudi_mor-> `commits show`
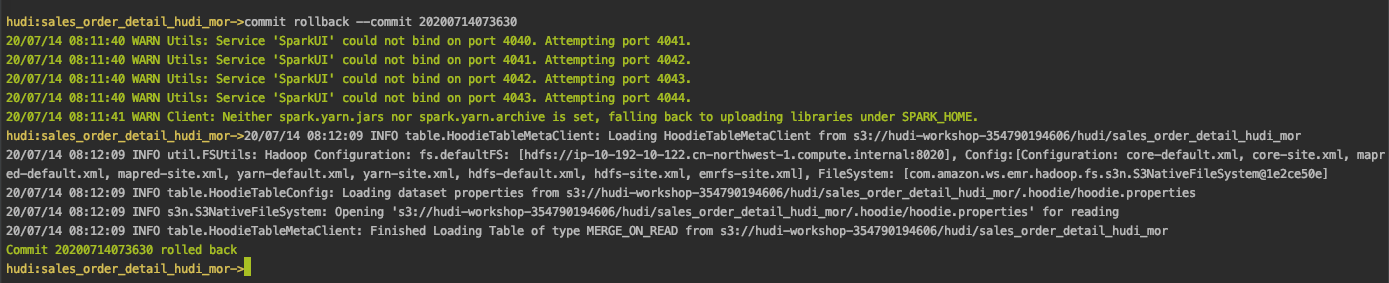
现在,我们可以查看压缩的“ sales_order_detail_hudi_mor”表以查看最新更改。让我们从Presto EMR集群中的Hive试试是否实现:
## 启动 hive cli
$> hive
## 查询更改的记录
hive> select record_key,quantity,month from sales_order_detail_hudi_mor where record_key = '<record_key>';

以上,您完成了实验2的内容
您也可以自己使用hive,presto,SPARK SQL进行查询,观察压缩前后的变化。
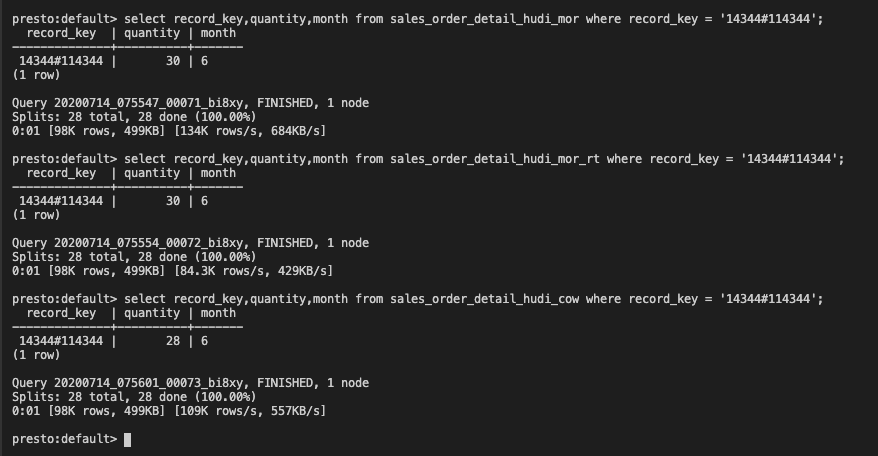
presto
mor执行压缩合并前
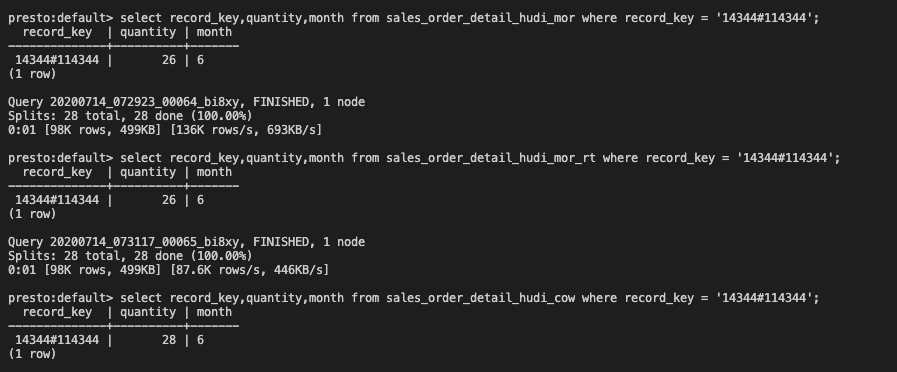
mor执行压缩合并后
spark
mor执行压缩合并前
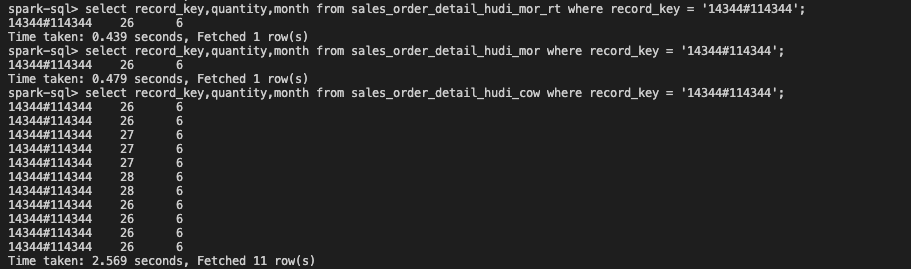
mor执行压缩合并后
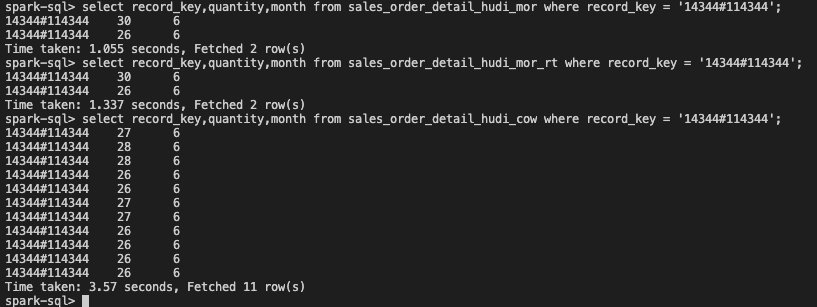
hive
mor执行压缩合并前
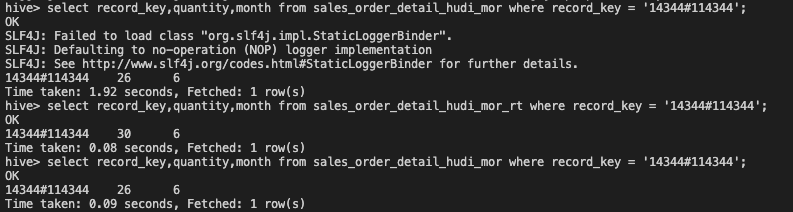
mor执行压缩合并后
