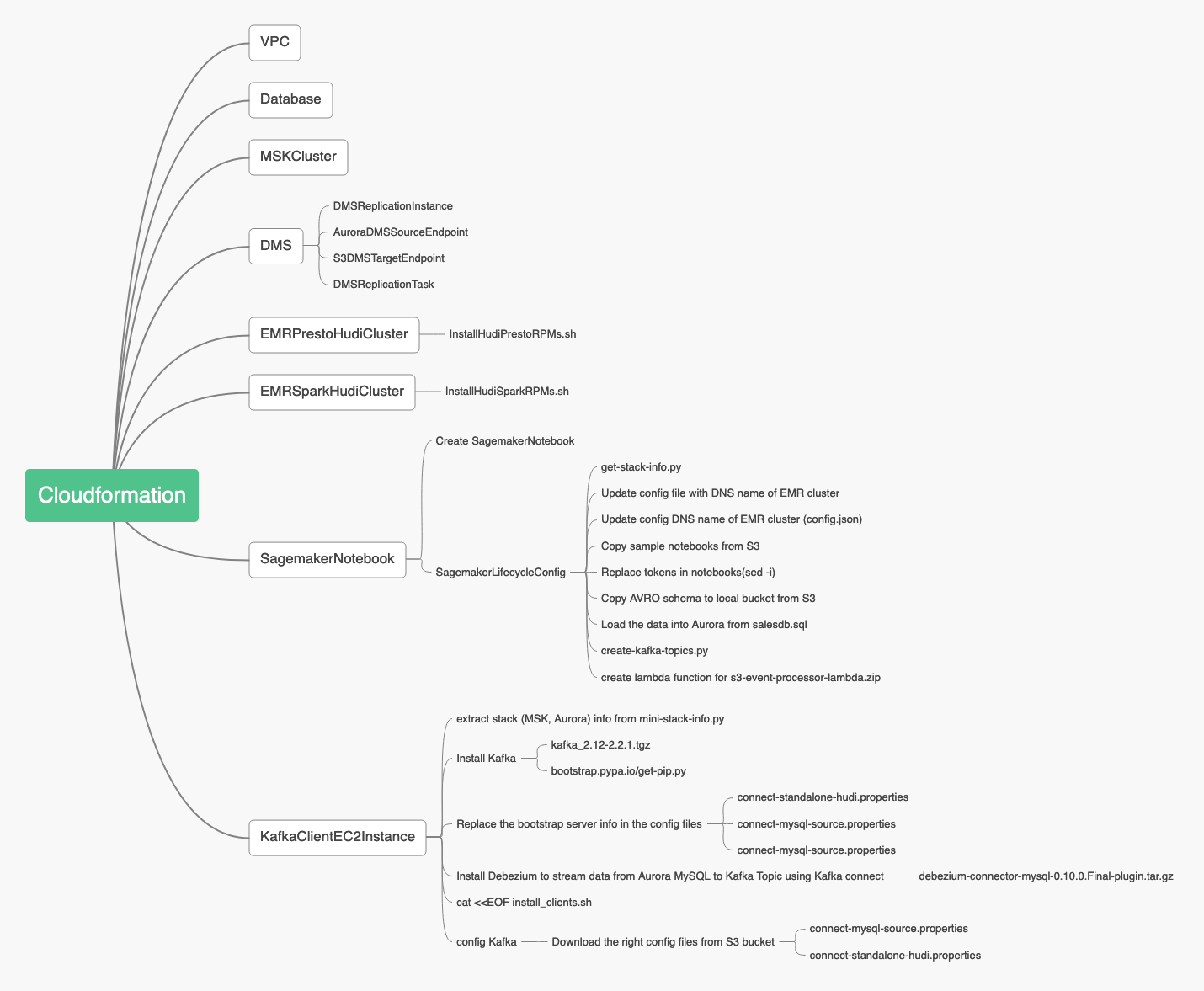
实验工作流
增量数据处理
在本实验中,我们将对Amazon S3上的数据集执行增量数据处理。数据湖的源数据来自Amazon Aurora数据库。我们将使用Amazon数据迁移服务(DMS)来提取全部负载,并将数据捕获(CDC)从Aurora集群(源)更改到Amazon S3(目标)。当文件到达S3时,将触发AWS Lambda函数,该函数从文件中读取数据并将其置于Amazon MSK主题中。 Spark Streaming 定义的作业从Amazon MSK主题读取数据,并将数据以Apache Hudi格式写入S3上的表中。
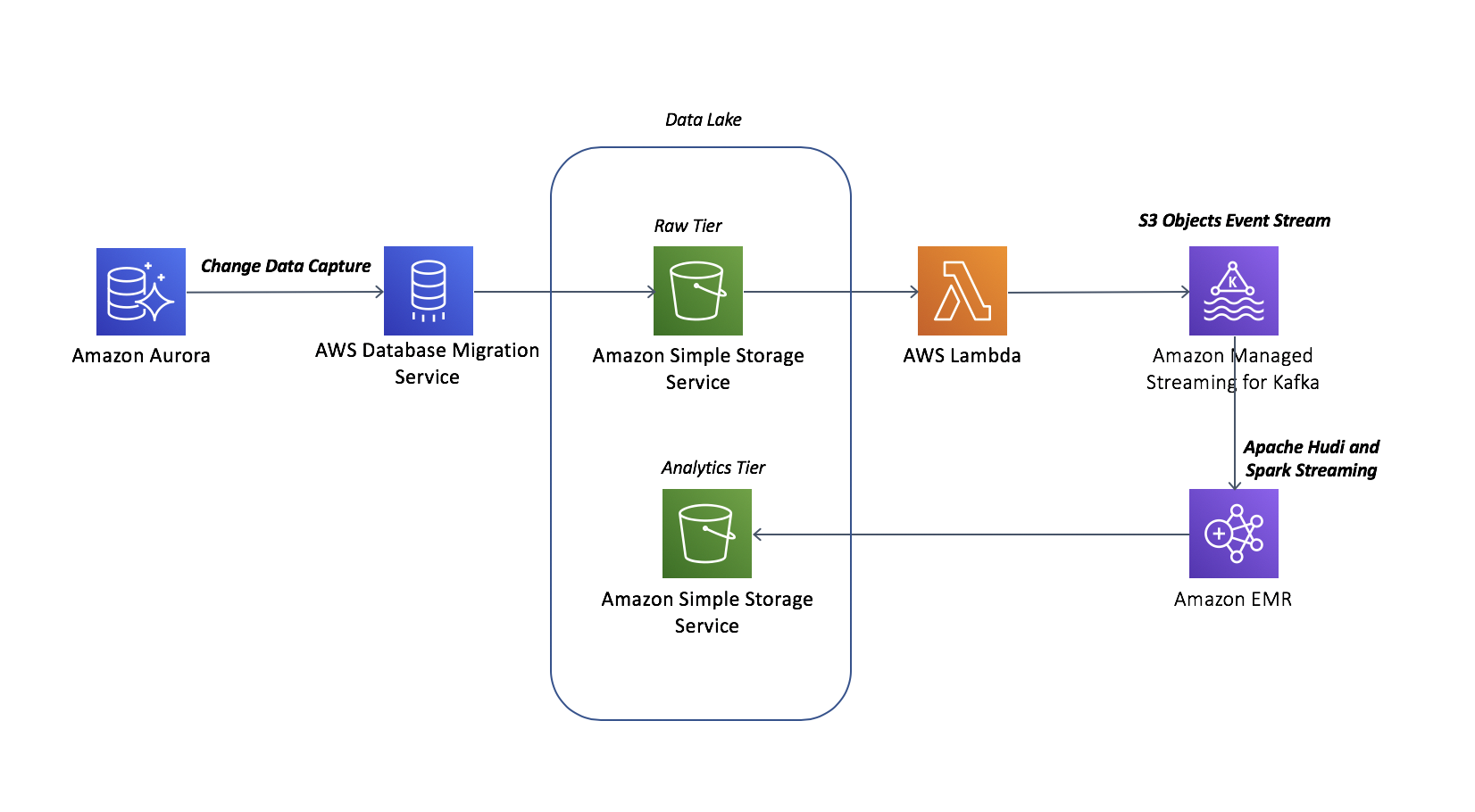
Cloudformation快速环境构建
如您所见,我们的实验涉及了数据库,Kafka,EMR,S3等多个基础设施,为简化我们的部署过程,我们将使用Cloudformation进行环境搭建,这大概需要30分钟
实验在Cloudformation堆栈部署环境的过程中涉及了以下自动化脚本,如您想要了解环境搭建的过程请您查阅如下的脚本代码及注释
| 脚本文件 | 功能概述 |
|---|---|
| hudi-workshop-template.yaml | Cloudformation自动化部署文件 |
| sagemaker_lifecycle.sh | 配置笔记本环境,调用脚本创建lambda,创建kafka topics,RDS加载数据等 |
| KafkaClientInstall.sh | 配置kafka客户端,运行数据管道创建脚本 |
| InstallHudiSparkRPMs.sh | 脚本在运行Spark 的EMR创建后自动运行,作用于Amazon EMR上安装Hudi补丁 |
| InstallHudiPrestoRPMs.sh | 脚本在运行Presto 的EMR创建后自动运行,作用于Amazon EMR上安装Hudi补丁 |
| salesdb.sql | Copy SQL Script |
| sales_order_detail.schema | Copy AVRO schema to local bucket |
| create-lambda-function.py | 在sagemaker笔记本中运行,create lambda function |
| get-stack-info.py | 获取环境中 (MSK, Aurora) 信息 |
| create-kafka-topics.py | create the kafka topics |
Cloudformation堆栈脚本逻辑如下图: